一、前言
有人好奇,XM POWER KIT是怎么在屏幕上显示文字的,尤其是支持各种各样的字体,下面我来进行简单的讲解~
硬件信息:
- 屏幕驱动:ST7789 (不重要,你能成功驱动屏幕即可)
- 批量刷屏函数(至少你有一个画点函数)
二、实现逻辑
要往屏幕显示文字,很容易想到下面这条逻辑链条(以显示单个字符为例):
- 1. 从字库中找到字符数据所在的位置
- 2. 知晓此字符的参数(宽度、高度、颜色等)
- 3. 准备字字符的数据
- 4. 将字符刷写到屏幕上
从上面的逻辑链条,我们就可以知道,要实现字符显示,需要实现下面这些:
- 怎么处理得到字符的字库?
- 怎么定位字符在字库中的位置?
- 怎么处理字符的数据?(怎么处理?怎么排列?)
- 怎么将字符刷写到屏幕上?
接下来我们依次来讲解:
1. 得到字库
为了方便的适配各种字体,我调教了半天豆包+kimi+grok,写出了下面这个字符取模工具:
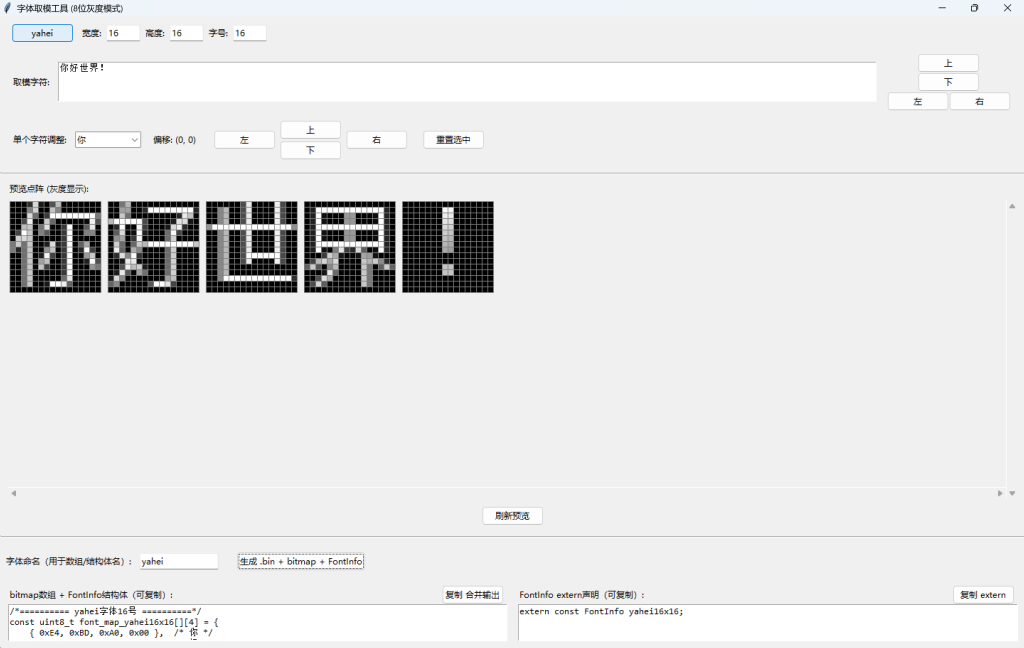
在实现这个应用之前,我们必须先约定一些信息,才能让STM32能正确使用到导出的字库:
1.1 字符编码
众所周知,每一个字符都有一个唯一的编码来表示它,为了方便,我们选择UTF8编码:UTF-8 是 Unicode 的变长字符编码,互联网常用,兼容 ASCII,字符长度 1 – 4 字节可变,不同字节数对应不同字符范围。
此外,UTF-8 依靠每个字节的高位固定前缀来判断当前字符的UTF8编码有几位,比如第一位编码:0xxxxxxx表示只有1位,110xxxxx表示2位长,1110xxxx表三位长….
举个简单的例子:
- ascii字符“A”:{ 0x41, 0x00, 0x00, 0x00 }
- 对于中文“国”:{0xE7,0xBD,0x8A,0x00}
ascii字符“A”,由于使用ascii字符,它只占用1字节的空间,剩下的字节填0;对于中文“国”,使用三个字节来编码,剩下的也是填0 。而在C语言里,获取字符的UTF8编码非常简单,比如字符char msg = “国”,我们直接*msg就能定位到此字符编码的首字符,(前提是你的编译器用的UTF8编码)。
因此,我们在STM32端就可以使用下面的函数来判断此字符的编码长度:
static inline uint8_t get_utf8_len(const char *str) {
uint8_t len = 0;
if ((*str & 0x80) == 0) {
len = 1; // ASCII
} else if ((*str & 0xE0) == 0xC0) {
len = 2; // 2字节UTF-8
} else if ((*str & 0xF0) == 0xE0) {
len = 3; // 3字节UTF-8
} else if ((*str & 0xF8) == 0xF0) {
len = 4; // 4字节UTF-8
}
return len;
}综上所述,我们只需要在生成字库的时候,记录下每个字符代码的UTF8编码,就近乎可以确认它在字库中的位置了,如下代码。(还需要每个字符的数据长度等信息,下面会讲).
const uint8_t font_map_JetBrainsMono16x22[][4] = {
{ 0x56, 0x00, 0x00, 0x00 }, /* V */
{ 0x41, 0x00, 0x00, 0x00 }, /* A */
{ 0x57, 0x00, 0x00, 0x00 }, /* W */
{ 0x4B, 0x00, 0x00, 0x00 }, /* K */
{ 0xCE, 0xA9, 0x00, 0x00 }, /* Ω */
};1.2 字符取模
首先,我们要规定取模的方向。我们可以将一个字符划分为n*m各小格子(如前图),取模方向就是说,我们是从上往下,从左往右 行优先这样子一行一行取模,还是说从上到下,从左到右 列优先这样一列一列取模。我们看大多数的屏幕驱动(ST7789 ,ILI9341等),在刷新屏幕的时候都是行优先,所以我们选取第一种方案。
其次,为了方便,我们规定:我们只保留字体数据,两个字体间的数据紧挨着一起。什么意思呢?就是我们不会存留任何文件头啊之类的数据,比如说你的字体大小是16*16,有5个字符,那么字库大小就是:
需要注意的是,这种方式需要外部记录字符排列的顺序。否则我们没法知道某一块数据表示什么字符。
1.3 字库保存
需要注意的是,为了抗锯齿,每一个格子就不再使用1bit来存储(只能表示亮灭),而是1个像素用8bit来表示,这样就有256种亮度了。
我们将所有字符取模,紧挨着拼接在一起,导出成xxx.bin文件来存储。我们只需要将它移动到FLASH中即可,STM32可以使用FATFS这样的文件系统来读取它。
2. 定位字符位置
前文提到,我们现在已经拿到了取模出的字库,接下来就是STM32端的主场了,我们来思考怎么定位到字符数据。
我们来想一想,每个字符的数据是紧密排列的,而且每个字符的尺寸是固定的(长*宽),我们就可以根据这个来判断!
我们定义下面这样一个结构体,来存储每一种字体的信息:
// 字体信息结构体
typedef struct {
uint8_t font_width; // 字体宽度
uint8_t font_height; // 字体高度
uint16_t font_num; // 字符个数
char path[FONT_PATH_MAX]; // 完整路径,例如 "0:/fonts/font16x16.bin"
const uint8_t (*font_map)[4]; // 查找表指针
} FontInfo;我们记录了此字体的长宽、数量、以及UTF8查找表。那么一个标准的字库就像下面这样:
/*========== JetBrainsMono字体26号 ==========*/
const uint8_t font_map_JetBrainsMono16x22[][4] = {
{ 0x56, 0x00, 0x00, 0x00 }, /* V */
{ 0x41, 0x00, 0x00, 0x00 }, /* A */
{ 0x57, 0x00, 0x00, 0x00 }, /* W */
{ 0x4B, 0x00, 0x00, 0x00 }, /* K */
{ 0xCE, 0xA9, 0x00, 0x00 }, /* Ω */
};
const FontInfo JetBrainsMono16x22 = {
.font_width = 16,
.font_height = 22,
.font_num = 5,
.path = "0:/font/JetBrainsMono16x22.bin",
.font_map = font_map_JetBrainsMono16x22
};UTF8查找表 + 结构体!我们就可以表示出一个字库我们所需要的信息了!
下面我们来演示一下怎么查找字库中某个字符,比如“W”:
// 在字体映射表中查找字符的索引
static int16_t find_char_index(const FontInfo *font, const char *string) {
uint8_t len = get_utf8_len(string);
if (len == 0) return 0;
for (uint16_t i = 0; i < font->font_num; i++) {
uint8_t *head = (uint8_t *) font->font_map[i];
if (memcmp(head, string, len) == 0) {
return i;
}
}
return -1; // 未找到,返回-1
}我们看此函数,它的作用很简单,拿着“W”字符的UTF8数据去查找表依次比较,比较成功就返回它在查找表中是第几位。比如说”W”,此函数就会返回i = 2;(第三个)。
接下来我们就可以定位到“W”在字库中数据的首位了,很简单,i * .font_width * .font_height 即可。
3. 准备字符数据
找到了字符数据所在的起始位置就很简单了,我们只需要准备一个足够大的缓冲区,从FLASH中读取 .font_width * .font_height 个字节的数据到缓冲区里即可。如果字符很大,那么写一个分块逻辑就行。
此外,我们还需要对数据进行处理,因为现在读到缓冲区的还是灰度数据,是没有颜色的!我们可以传入字体颜色和底色,进行一个简单的alpha混合:就可以很大程度的改善显示效果,避免锯齿!
// RGB565通道拆分/合并宏
#define RGB565_GET_R(color) (((color) >> 11) & 0x1F)
#define RGB565_GET_G(color) (((color) >> 5) & 0x3F)
#define RGB565_GET_B(color) ((color) & 0x1F)
#define RGB565_MERGE(r, g, b) (((r & 0x1F) << 11) | ((g & 0x3F) << 5) | (b & 0x1F))
// 批量灰度图转RGB565
static void batch_gray_to_rgb565(const uint8_t *gray_buf, uint16_t *flush_buf, uint32_t pixel_num, uint16_t ftColor,
uint16_t bgColor) {
register uint8_t ft_r = RGB565_GET_R(ftColor);
register uint8_t ft_g = RGB565_GET_G(ftColor);
register uint8_t ft_b = RGB565_GET_B(ftColor);
register uint8_t bg_r = RGB565_GET_R(bgColor);
register uint8_t bg_g = RGB565_GET_G(bgColor);
register uint8_t bg_b = RGB565_GET_B(bgColor);
volatile uint32_t i;
uint32_t remain = pixel_num % 4; // 处理不能被4整除的剩余像素
uint32_t main_num = pixel_num - remain;
// 主循环:每次处理4个像素,减少循环次数
for (i = 0; i < main_num; i += 4) {
// 像素1
uint8_t g1 = gray_buf[i];
uint32_t r1 = bg_r * (255 - g1) + ft_r * g1;
uint32_t g1_ = bg_g * (255 - g1) + ft_g * g1;
uint32_t b1 = bg_b * (255 - g1) + ft_b * g1;
flush_buf[i] = RGB565_MERGE((r1+127)/255, (g1_+127)/255, (b1+127)/255);
// 像素2
uint8_t g2 = gray_buf[i + 1];
uint32_t r2 = bg_r * (255 - g2) + ft_r * g2;
uint32_t g2_ = bg_g * (255 - g2) + ft_g * g2;
uint32_t b2 = bg_b * (255 - g2) + ft_b * g2;
flush_buf[i + 1] = RGB565_MERGE((r2+127)/255, (g2_+127)/255, (b2+127)/255);
// 像素3
uint8_t g3 = gray_buf[i + 2];
uint32_t r3 = bg_r * (255 - g3) + ft_r * g3;
uint32_t g3_ = bg_g * (255 - g3) + ft_g * g3;
uint32_t b3 = bg_b * (255 - g3) + ft_b * g3;
flush_buf[i + 2] = RGB565_MERGE((r3+127)/255, (g3_+127)/255, (b3+127)/255);
// 像素4
uint8_t g4 = gray_buf[i + 3];
uint32_t r4 = bg_r * (255 - g4) + ft_r * g4;
uint32_t g4_ = bg_g * (255 - g4) + ft_g * g4;
uint32_t b4 = bg_b * (255 - g4) + ft_b * g4;
flush_buf[i + 3] = RGB565_MERGE((r4+127)/255, (g4_+127)/255, (b4+127)/255);
}
// 处理剩余像素
for (; i < pixel_num; i++) {
uint8_t g = gray_buf[i];
uint32_t r = bg_r * (255 - g) + ft_r * g;
uint32_t g_ = bg_g * (255 - g) + ft_g * g;
uint32_t b = bg_b * (255 - g) + ft_b * g;
flush_buf[i] = RGB565_MERGE((r+127)/255, (g_+127)/255, (b+127)/255);
}
}别看着很长,其实是为了效率才这么写的,一次性处理4个像素,便于编译器优化~
4. 刷新屏幕
现在就很简单了,我们在第三步以及得到了存储着RGB565数据的缓冲区,我们只需要设置好屏幕的刷新范围,然后将缓冲区数据一股脑刷上去就行~
至于数据的排列顺序,我们在取模导出的时候就已经处理好了,这里就不需要做任何处理。
三、总结
综上,我们可以将这些步骤合并成一个函数:
// 绘制单个字符(作为绘制字符串的底层函数,外部接口为 GFX_DrawString)
static void GFX_DrawChar(FIL *FIL, uint16_t x, uint16_t y, const char *ch, const FontInfo *font,
uint16_t ftColor, uint16_t bgColor, uint8_t *gray_buffer, uint16_t *flush_buffer) {
int16_t index = find_char_index(font, ch); // 获取字符索引
if (index == -1) { return; } // 字符未找到,直接返回
uint32_t pixel_num = font->font_width * font->font_height; // 计算像素总数
if (FIL == NULL || gray_buffer == NULL || flush_buffer == NULL) {
return; // 参数检查,确保指针有效
}
// 从文件中读取字模数据到灰度缓冲区
res = f_lseek(FIL, index * pixel_num); // 定位到字模数据位置
if (res != FR_OK) { return; }
res = f_read(FIL, gray_buffer, pixel_num, &br); // 读取字模数据
if (res != FR_OK || br != pixel_num) { return; } // 读取失败或字节数不匹配
// 根据灰度数据,融合前景色和背景色生成最终的RGB565数据到Flush_Buffer
batch_gray_to_rgb565(gray_buffer, flush_buffer, pixel_num, ftColor, bgColor);
// 设置LCD窗口并使用DMA发送Flush_Buffer数据到LCD
LCD_SET_WINDOWS(x, y, x + font->font_width - 1, y + font->font_height - 1);
LCD_FLUSH_DMA((uint32_t) flush_buffer, pixel_num);
}如果是字符串,循环上面的绘制单个字符的代码就行了~
这里的参数意义如下:
- 字符串左上角的坐标(x , y)
- 你要打印的字符串指针 str
- 你选用的字体结构体 font
- 字体颜色 ftColor
- 背景颜色 bgColor
- 字符间距 spacing
void GFX_DrawString(uint16_t x, uint16_t y, const char *str, const FontInfo *font,
uint16_t ftColor, uint16_t bgColor, int8_t spacing) {
if (str == NULL || font == NULL) {
return; // 参数检查,确保指针有效
}
res = f_open(&fil, font->path, FA_READ);
if (res != FR_OK) {
return; // 打开字体文件失败
}
uint32_t pixel_num = font->font_width * font->font_height;
uint8_t *gray_buffer = malloc(pixel_num); // 字模灰度缓冲区
uint16_t *flush_buffer = malloc(pixel_num * 2); // RGB565缓冲区
if (gray_buffer == NULL || flush_buffer == NULL) {
f_close(&fil);
if (gray_buffer) free(gray_buffer);
if (flush_buffer) free(flush_buffer);
return; // 内存分配失败
}
uint16_t cursor_x = x;
const char *p = str;
while (*p) {
uint8_t utf8_len = get_utf8_len(p);
if (utf8_len == 0) break; // 无效UTF-8编码,停止处理
// 1. 先获取字符索引(提前判断是否找到字符)
int16_t char_index = find_char_index(font, p);
// 2. 判断是否为小数点(.):仅单字节ASCII 0x2E
uint8_t is_dot = (utf8_len == 1 && (uint8_t) *p == 0x2E) ? 1 : 0;
uint16_t char_step = 0; // 初始化字符步进值
// 3. 核心逻辑:根据字符是否找到 + 是否为小数点,计算步进值
if (char_index == -1) {
// 字符未找到:步进值 = 0.7 * 字体宽度 向上取整
char_step = (uint16_t) ceil(font->font_width * 0.7f);
} else if (is_dot) {
// 小数点:使用原有有效宽度
char_step = get_dot_effective_width(font);
} else {
// 普通字符(找到):使用原有完整宽度
char_step = font->font_width;
}
// 4. 仅当字符找到时,才绘制字符
if (char_index != -1) {
if (is_dot) {
GFX_DrawDotChar(&fil, cursor_x, y, p, font, ftColor, bgColor, gray_buffer, flush_buffer);
} else {
GFX_DrawChar(&fil, cursor_x, y, p, font, ftColor, bgColor, gray_buffer, flush_buffer);
}
}
// 5. 字体间隔绘制(原有逻辑保留)
if (spacing > 0 && *(p + utf8_len) != '\0') {
int16_t spacing_x1 = cursor_x + char_step;
int16_t spacing_x2 = spacing_x1 + spacing - 1;
uint16_t spacing_y1 = y;
uint16_t spacing_y2 = y + font->font_height - 1;
GFX_DrawRect(spacing_x1, spacing_y1, spacing_x2, spacing_y2, bgColor, 1);
}
// 6. 移动游标:字符步进值 + 字间距(兼容正负)
cursor_x += (char_step + spacing);
p += utf8_len; // 移动到下一个UTF-8字符
}
free(gray_buffer);
free(flush_buffer);
f_close(&fil);
}好了,简单过了一遍,大体的逻辑就是这样子,细节的话可以看看原代码~







讲解得很详细,学到了很多STM32屏幕显示的知识!