示波器可以说是我做过最最最复杂的东西了,前前后后搞了快1个月才搞好。下面随我的步伐,我们进行细致的讲解~
一、硬件设计
1、前级电路
对于一个输入信号,我们需要对其进行一些处理,比如说 是直流耦合还是交流耦合?要不要对它进行分压?分压后要不要进行放大?等等等等。无论如何,我们的目的都是将输入信号进行适当的处理,让它适合STM32 3.3V的ADC采样。因此就有了如下的电路:
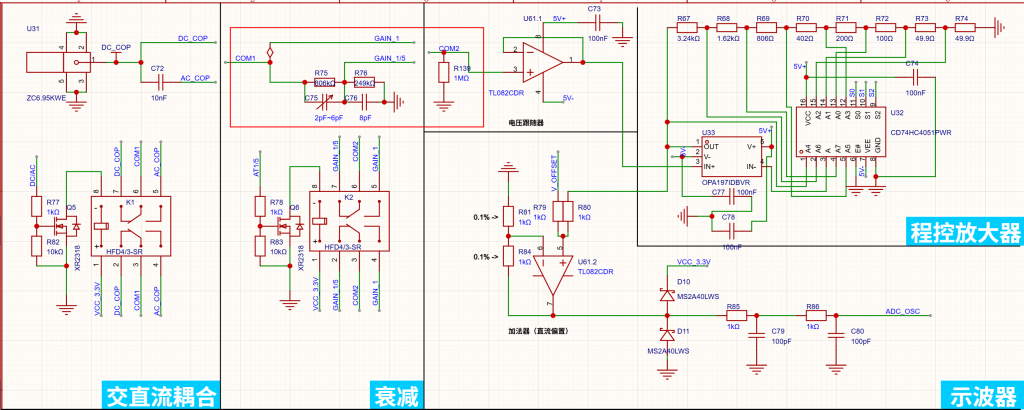
我们来依次分析一下:
1.1 交直流耦合与衰减
这里使用了两套继电器来分别控制。交直流耦合很简单,直流就直接过,交流耦合就经过一个10nf的电容滤除直流分量即可。
衰减同理,不过这里的衰减倍数要重新计算一下:

由于1MΩ的下拉电阻存在,同时为了保证示波器输入端1MΩ的阻抗需求,才进行此电阻网络设计。
经过这两步骤处理后,信号经过一个电压跟随器提升带载能力,避免干扰~
1.2 程控放大器
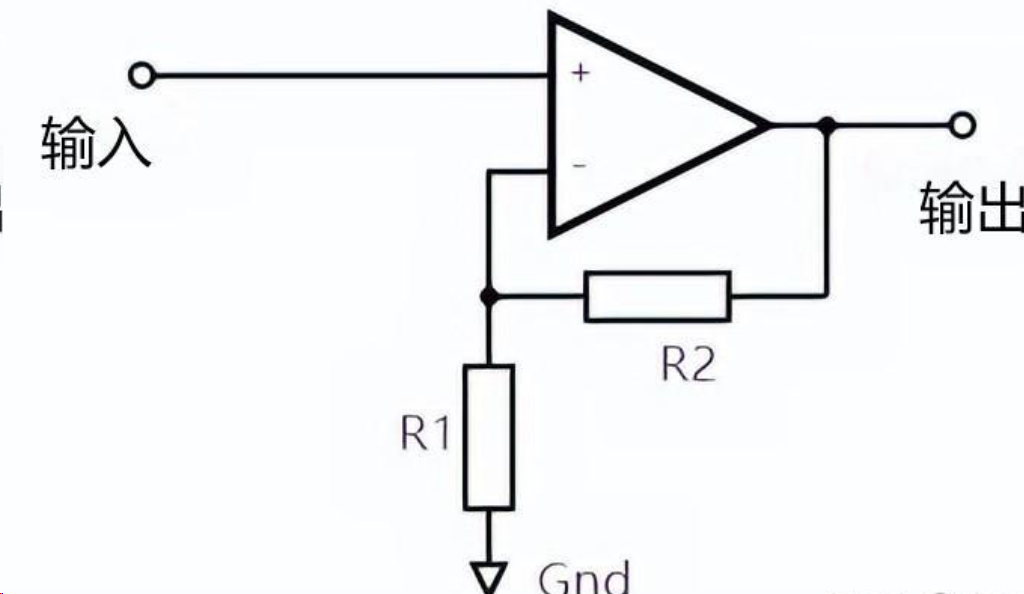
这里的原理其实很简单,OPA197作为同相放大器的主运放,CD74HC4051就是一个1对8的模拟开关,相当于你面前有8条路,一次只能走一条。我们看一下这一串电阻网络:
运放输出 —A— R1 —B— R2 —C— R3 —D— R4 —E— R5 —F— R6 —G — R7 —H— R8 — GND
CD74HC4051会将运放的反向端连接到A~H这8个节点中的一个,此时节点左端的电阻之和就是R2,右端电阻之和就是R1,那么根据公式,放大增益就是:
举个例子,假如CD74HC4051将 E 点连接到了运放反向端,那么:
也就是16倍放大~
1.3 加法器
这里没什么好讲的,作用就是将放大后的信号(有正有负)抬升1.65V送往ADC,这样就可以处理负电平信号了~
2、触发器
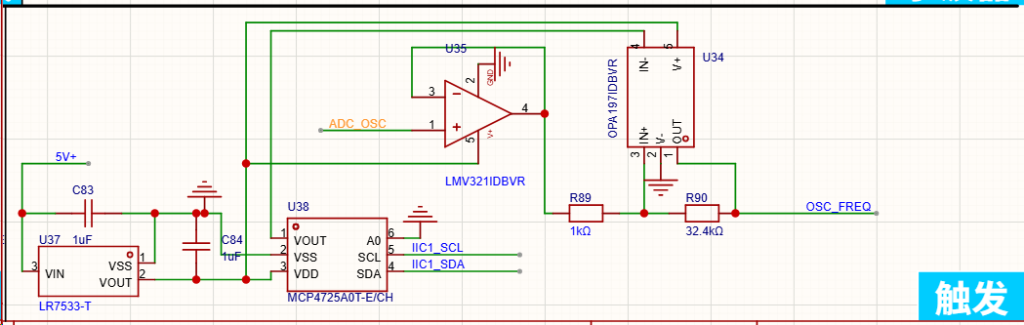
触发器的全称叫施密特触发器,这是一种具有迟滞的比较器电路,通过向比较器或差分放大器的同相输入端施加正反馈来实现。施密特触发器使用两个输入不同的阈值电压电平来避免输入信号中的噪声,这种双阈值的作用称为滞后。
这里,前级电路最终输出的信号先经过U35这个电压跟随器,目的是避免触发器触发时造成了波形阶梯。MCP4725的作用就是调节触发电压。
当波形电压达到下阈值电压时,U34输出发出一个上升边压,STM32检测后即可做出响应~
二、软件部分
这部分由豆包代为总结~
本解析完全聚焦于数据采集、数据处理、波形显示三大核心链路,基于提供的源码进行底层机理级别的详细拆解,不涉及任何UI交互逻辑。
一、数据采集链路:硬件时序与环形缓冲
数据采集是示波器的“信号入口”,核心目标是无丢失、高精度、时序可控地将外部模拟电压转换为数字样本流。本设计采用“ADC+定时器触发+DMA环形缓冲”的经典架构。
1.1 硬件采集架构初始化
ADC配置(8位分辨率、TIM8触发)
// 摘自 DSO_ADC_Init()
hadc1.Init.Resolution = ADC_RESOLUTION_8B; // 8位分辨率(0-255)
hadc1.Init.ContinuousConvMode = DISABLE; // 非连续转换(由TIM8触发)
hadc1.Init.ExternalTrigConvEdge = ADC_EXTERNALTRIGCONVEDGE_RISING;
hadc1.Init.ExternalTrigConv = ADC_EXTERNALTRIGCONV_T8_TRGO; // TIM8 TRGO触发
hadc1.Init.DMAContinuousRequests = ENABLE; // 开启DMA连续请求深度机理:
- 8位分辨率选择:不同于万用表追求高精度,示波器追求高采样率。8位分辨率(0-255)将单样本数据量压缩至1字节,在相同DMA带宽下可实现更高的采样吞吐,且256级灰度对于波形显示已足够。
- TIM8触发源:ADC不自由运行,而是由TIM8的TRGO(触发输出)信号严格定时触发。这保证了采样间隔的精确性(无时钟抖动),是后续时域测量(频率、周期)的基础。
- DMA连续请求:ADC转换完成后自动向DMA发请求,无需CPU干预,实现“采样即传输”。
DMA配置(环形模式、字节对齐)
hdma_adc1.Instance = DMA2_Stream4;
hdma_adc1.Init.Direction = DMA_PERIPH_TO_MEMORY; // 外设(ADC)到内存
hdma_adc1.Init.PeriphInc = DMA_PINC_DISABLE; // 外设地址固定(ADC数据寄存器)
hdma_adc1.Init.MemInc = DMA_MINC_ENABLE; // 内存地址递增
hdma_adc1.Init.PeriphDataAlignment = DMA_PDATAALIGN_BYTE;
hdma_adc1.Init.MemDataAlignment = DMA_MDATAALIGN_BYTE;
hdma_adc1.Init.Mode = DMA_CIRCULAR; // 环形模式深度机理:
- 环形模式(CIRCULAR):这是连续采集的关键。DMA将内存缓冲区视为一个环,写指针到达缓冲区末尾后自动绕回开头。配合下文的“触发后截取”机制,完美解决了“触发前数据保存”的难题(示波器需要看到触发点之前的波形)。
- 字节对齐:与ADC 8位分辨率配合,单字节传输最大化DMA效率,避免总线宽度浪费。
全局采集缓冲区定义
// 摘自 DsoCoreTask.h
#define DSO_Buffer_Size 5632
static uint8_t DSO_ADC_BUFFER[DSO_Buffer_Size] = {0};深度机理:
- 5632字节的容量设计:这不是随意值。后文定义了
PRE_TRIGGER_POINTS = 1440和POST_TRIGGER_POINTS = 1440,即单次显示需要 1440(前) + 1(触发) + 1440(后) = 2881 个点。 - 缓冲区大小 5632 ≈ 2 × 2881,保证了在环形缓冲中,即使触发点在边界,也有足够的空间容纳前后各1440个点而不发生覆盖。
1.2 采样时序与触发捕获
定时器链路(TIM8 + TIM3 + TIM11)
系统包含三个定时器,各司其职:
- TIM8:ADC采样时钟源,产生恒定频率的TRGO信号触发ADC。
- TIM3:硬件边沿触发捕获,检测模拟信号的上升/下降沿。
- TIM11:自动触发定时器,在无硬件触发时产生定时触发。
核心中断回调:触发时刻的NDTR快照
// 触发事件处理函数
static void TriggerHandler(void) {
if (Is_Trig) return; // 防重入
// 关闭触发中断
__HAL_TIM_DISABLE_IT(&htim3, TIM_IT_CC3);
HAL_TIM_Base_Stop_IT(&htim11);
Is_Trig = true;
// 【核心】记录触发时刻DMA的剩余计数寄存器(NDTR)
trigger_pos = (DSO_Buffer_Size - trigger_ndtr_at_capture) % DSO_Buffer_Size;
post_trigger_counting = true;
}深度机理(这是示波器采集最核心的机理):
- NDTR寄存器的作用:DMA的
NDTR(Number of Data Register) 寄存器记录了剩余待传输的数据量。 - 触发位置计算:
- DMA初始装载值为
DSO_Buffer_Size(5632)。 - 随着采样进行,NDTR从5632递减。
- 在触发发生的瞬间,CPU快照读取
trigger_ndtr_at_capture。 - 通过公式
trigger_pos = (BufferSize - NDTR) % BufferSize,精确计算出触发点在环形缓冲区中的绝对索引位置。 - 这就是“预触发”(Pre-trigger)的硬件基础:即使触发发生在现在,我们也能通过环形缓冲区中保存的历史数据,还原出触发发生之前的波形。
后触发采样完成判断
// ADC半转换/全转换完成回调
void CB_ADC_HalfConvCplt(ADC_HandleTypeDef *hadc) {
if (!post_trigger_counting) return;
// 计算当前已采集的“后触发点数”
uint32_t current_ndtr = __HAL_DMA_GET_COUNTER(&hdma_adc1);
uint32_t post = (trigger_ndtr_at_capture - current_ndtr + DSO_Buffer_Size) % DSO_Buffer_Size;
// 后触发点数达标,停止采集
if (post >= POST_TRIGGER_POINTS) {
AdcTim_OFF();
Is_conv_finish = true;
post_trigger_counting = false;
}
}深度机理:
- 触发发生后,并不立即停止采集,而是开启
post_trigger_counting状态。 - 继续采集
POST_TRIGGER_POINTS(1440) 个点后才停止。 - 至此,环形缓冲区中包含了完整的“触发前1440点 + 触发点 + 触发后1440点”,一帧波形的数据原料准备完毕。
二、数据处理链路:从Raw Data到显示缓存
数据处理链路是示波器的“算法核心”,承接原始ADC数据,输出最终的显示像素数据。包含解交错重排、时基插值、电压校准、峰值抽取、软件触发微调五大步骤。
2.1 第一步:环形缓冲区数据重排(SortRawSamplesToBuffer)
虽然环形缓冲区里有数据,但它是“环”状的,且触发点位置随机。需要将其“拉直”并排序为线性的“触发前-触发点-触发后”结构。
static void SortRawSamplesToBuffer(uint32_t trigger_pos) {
const uint32_t pre_len = PRE_TRIGGER_POINTS; // 1440
const uint32_t post_len = POST_TRIGGER_POINTS;// 1440
// 1. 复制触发前数据(Pre-trigger)
if (trigger_pos >= pre_len) {
// 情况A:触发点位置足够靠后,前1440点是连续的
memcpy(raw_sorted_buf, &DSO_ADC_BUFFER[trigger_pos - pre_len], pre_len);
} else {
// 情况B:触发点靠近缓冲区开头,前1440点跨了环形边界
// 需要分两段拷贝:[末尾一段] + [开头一段]
uint32_t len1 = pre_len - trigger_pos;
memcpy(raw_sorted_buf, &DSO_ADC_BUFFER[DSO_Buffer_Size - len1], len1);
memcpy(raw_sorted_buf + len1, DSO_ADC_BUFFER, trigger_pos);
}
// 2. 复制触发点本身
raw_sorted_buf[pre_len] = DSO_ADC_BUFFER[trigger_pos];
// 3. 复制触发后数据(Post-trigger)
uint32_t next_pos = (trigger_pos + 1) % DSO_Buffer_Size;
if (next_pos + post_len <= DSO_Buffer_Size) {
// 连续拷贝
memcpy(&raw_sorted_buf[pre_len + 1], &DSO_ADC_BUFFER[next_pos], post_len);
} else {
// 跨边界分段拷贝
uint32_t len1 = DSO_Buffer_Size - next_pos;
memcpy(&raw_sorted_buf[pre_len + 1], &DSO_ADC_BUFFER[next_pos], len1);
memcpy(&raw_sorted_buf[pre_len + 1 + len1], DSO_ADC_BUFFER, post_len - len1);
}
}深度机理:
- 输入:环形缓冲区
DSO_ADC_BUFFER[5632]和随机的trigger_pos。 - 输出:线性缓冲区
raw_sorted_buf[2881]。 - 索引映射:
raw_sorted_buf[0..1439]:触发前1440个点。raw_sorted_buf[1440]:精确的触发点。raw_sorted_buf[1441..2880]:触发后1440个点。- 环形边界处理:代码中大量的
if-else和memcpy分段操作,都是为了处理环形缓冲区的“回绕”(Wrap-around)问题,确保数据在时间上是连续的。
2.2 第二步:时基拉伸与电压校准(ApplyStretchToBuffer)
这是最复杂的一步,包含时基插值(时域缩放)和电压校准(幅值缩放与偏置)。
2.2.1 时基拉伸(Catmull-Rom插值)
当用户旋转旋钮切换到“高倍时基”(如5us/格)时,屏幕上的每个像素对应极短的时间。此时原始采样点可能不够密集,需要通过插值算法在点与点之间“插入”新的点,实现波形的平滑拉伸。
// Catmull-Rom 插值算法
static uint8_t CatmullRomInterp(uint8_t p0, uint8_t p1, uint8_t p2, uint8_t p3, float t) {
float t2 = t * t;
float t3 = t2 * t;
// 经典Catmull-Rom公式:保证经过p1和p2,且一阶导数连续
float a = -0.5f * p0 + 1.5f * p1 - 1.5f * p2 + 0.5f * p3;
float b = p0 - 2.5f * p1 + 2.0f * p2 - 0.5f * p3;
float c = -0.5f * p0 + 0.5f * p2;
float d = p1;
float value = a * t3 + b * t2 + c * t + d;
// 钳位到0-255
if (value < 0.0f) return 0;
if (value > 255.0f) return 255;
return (uint8_t)value;
}
// 拉伸处理主逻辑
if (stretch_factor <= 1.1f) {
memcpy(stretched_buf, raw_sorted_buf, SORTED_BUF_SIZE);
} else {
for (int i = 0; i < SORTED_BUF_SIZE; i++) {
float raw_pos = i / stretch_factor;
uint8_t max_val = 0;
// 【技巧】多组插值取最大值,保留峰值信息
for (int k = -6; k <= 6; k++) {
float pos = raw_pos + k * 0.15f;
// ... 边界检查 ...
int32_t idx = (int32_t)pos;
float t = pos - idx; // 插值系数 t (0~1)
// 取相邻四个点用于插值
uint8_t p0 = raw_sorted_buf[(idx-1 < 0) ? 0 : idx-1];
uint8_t p1 = raw_sorted_buf[idx];
uint8_t p2 = raw_sorted_buf[(idx+1 >= SORTED_BUF_SIZE) ? SORTED_BUF_SIZE-1 : idx+1];
uint8_t p3 = raw_sorted_buf[(idx+2 >= SORTED_BUF_SIZE) ? SORTED_BUF_SIZE-1 : idx+2];
uint8_t interp_val = CatmullRomInterp(p0, p1, p2, p3, t);
if (interp_val > max_val) max_val = interp_val;
}
stretched_buf[i] = max_val;
}
}深度机理:
- 为什么选Catmull-Rom?:
- 相比于线性插值(折线),它能生成平滑的曲线。
- 相比于样条插值,它计算量小,且保证曲线严格经过原始采样点(p1和p2),不失真。
- 峰值保留技巧(Max-Val):
- 代码没有只插值一次,而是在
k = -6到6的范围内插值了13次,取最大值。 - 这是为了防止在高倍拉伸时,由于插值的平滑效应导致窄脉冲峰值被“磨平”。取最大值能保留信号的峰值信息。
2.2.2 电压校准与缩放
插值完成后,进行零点偏置校正和电压档位缩放。
// 1. 根据电压档位获取对应的零点校正量
int16_t offset_calib = 0;
switch (V_div) {
case div_10mv: offset_calib = UserParam.OSC_Original_X32; break;
// ... 其他档位 ...
}
// 2. 应用校正与缩放
for (int i = 0; i < SORTED_BUF_SIZE; i++) {
const int16_t IDEAL_ORIGIN = 128; // 理想零点(8位ADC中点)
float code = (float)stretched_buf[i];
// 步骤A:零点偏置校正
// 硬件误差会导致0V输入时ADC读数不是128,这里加回校正量
float calibrated_code = code + (float)offset_calib;
// 步骤B:围绕理想原点进行电压缩放
// 公式:Final = 128 + (Calibrated - 128) * ZoomFactor
float final_code = (float)IDEAL_ORIGIN +
(calibrated_code - (float)IDEAL_ORIGIN) * div_base[V_div].zoom_factor;
// 步骤C:钳位回8bit范围
stretched_buf[i] = (uint8_t) CLAMP(final_code, 0.0f, 255.0f);
}深度机理:
- 零点校正(Offset Calibration):由于硬件运放的失调电压,当输入短路(0V)时,ADC读数可能不是理想的128(中点)。
UserParam.OSC_Original_XXX存储了校准值,用于修正这个偏差。 - 围绕原点缩放:
- 先将值减去128,得到“相对于零点的差值”。
- 乘以
zoom_factor(根据电压档位,如10mV/格、500mV/格)。 - 再加回128。
- 这种操作保证了波形是以屏幕中心为基准进行缩放的,调整电压档位时,波形中心不会漂移。
2.3 第三步:峰值抽取构建显示缓存(DSO_BuildShowBuffer)
现在我们有2881个处理好的数据点,但屏幕宽度有限(代码中逻辑对应约600个显示点)。需要将2881个点压缩到601个点(DSO_ShowBuffer_Deep = 601)。
简单的“抽点”(每隔几个点取一个)会丢失峰值信息。本设计采用峰值抽取(Peak Detection)算法。
void DSO_BuildShowBuffer(void) {
// 处理前触发区域(0~299):1440点 -> 300点
for (int show_idx = 0; show_idx < 300; show_idx++) {
// 计算当前显示点对应的原始数据区间 [m_start, m_end]
uint32_t m_start = (show_idx * PRE_TRIGGER_POINTS) / 300;
uint32_t m_end = (((show_idx + 1) * PRE_TRIGGER_POINTS) + 299) / 300 - 1;
uint8_t max_val = 0;
// 【核心】在区间内寻找最大值(峰值抽取)
for (uint32_t m = m_start; m <= m_end; m++) {
uint8_t val = stretched_buf[m];
if (val > max_val) max_val = val;
}
DSO_SAMPLE_SHOW_BUFFER[show_idx] = max_val;
}
// 处理触发点(300)
DSO_SAMPLE_SHOW_BUFFER[300] = stretched_buf[PRE_TRIGGER_POINTS];
// 处理后触发区域(301~600):1440点 -> 300点
// ... 逻辑同上,峰值抽取 ...
}深度机理:
- 峰值抽取 vs 简单抽点:
- 如果简单抽点,可能刚好漏掉窄脉冲的峰值,导致波形看起来幅度变小。
- 峰值抽取:对于每一个屏幕像素点,回看对应的一小段原始数据,取这段数据里的最大值(或最小值,或峰峰值连线,本代码取Max)。
- 这保证了即使在很低的时基档位(压缩很厉害),信号的峰值细节也不会丢失,这是专业示波器的标配算法。
2.4 第四步:软件触发微调(Software_Trigger_FineTune)
虽然硬件触发已经很准,但由于DMA延迟、中断延迟等,触发点在屏幕上可能不是完美居中。代码进行了一次软件层面的二次搜索。
static int16_t Software_Trigger_FineTune(const uint8_t* buffer, EdgeType_e edge_type) {
const int16_t center = 300; // 屏幕中心理想位置
const int16_t search_range = 125;
uint8_t threshold_value = 127 + trigger_offset;
int16_t best_offset = 0;
int32_t best_score = -1;
// 在中心附近搜索最佳触发点
for (int16_t i = center - search_range; i <= center + search_range; i++) {
// 计算边沿变化率
uint8_t pos1 = buffer[i-1];
uint8_t pos2 = buffer[i+1];
int16_t diff = (int16_t)pos2 - (int16_t)pos1;
// 判断是否为有效边沿(斜率够大 + 电压接近阈值)
bool is_valid_edge = (diff > edge_threshold) &&
(abs((int16_t)buffer[i] - threshold_value) <= voltage_window);
// 评分机制:越靠近中心分越高
if (is_valid_edge) {
int16_t offset = i - center;
int32_t score = 10000 - abs(offset) * 100;
if (score > best_score) {
best_score = score;
best_offset = offset;
}
}
}
return best_offset;
}深度机理:
- 这是一个基于评分的搜索算法。
- 它在显示缓冲区的中心附近(±125点)再次搜索满足条件的边沿。
- 评分标准:
- 必须是上升/下降沿(
diff足够大)。 - 电压必须接近设定的触发电平。
- 位置越靠近屏幕中心(300),得分越高。
- 返回
best_offset,在最终绘制时用于水平偏移,确保波形完美地“钉”在屏幕中心。
三、波形显示链路:从数据到像素
显示链路的核心挑战是避免屏闪和高效绘制。本设计采用屏幕分块刷新和网格/波形混合缓冲技术。
3.1 显示预备:查找表与网格数据
Y坐标查找表(y_lookup)
// 摘自 DsoSources.c
// 将8位ADC值(0-255)映射到屏幕高度(0-200)
const uint8_t y_lookup[256] = {
200, 200, 199, 198, ... , 1, 0
};深度机理:
- 这是一个硬编码的查找表(LUT)。
- 目的是将ADC值(0-255)非线性地映射到屏幕的Y坐标(0-200)。
- 使用LUT避免了在绘制时进行耗时的浮点除法运算 (
Y = 200 - (Val * 200 / 255)),直接查表,极快。
网格位图数据(grid_data)
// 201行 × 38列的位图
// 每一字节存储8个水平像素点(bit7是左,bit0是右)
const uint8_t grid_data[201][38] = {
{0xff, 0xff, ... , 0xf8}, // 第0行(顶部边框)
{0x80, 0x00, ... , 0x08}, // 第1行
// ...
};深度机理:
- 这不是代码生成的,是预编译的位图常量。
- 它以极高的效率存储了示波器的背景网格(坐标线)。
- 内存布局:
grid_data[行][列字节]。例如grid_data[100][0]的第7个bit为1,代表第100行、第0列的像素是网格点。
3.2 核心绘制:无闪烁分块渲染(Refresh_DSO_Waveform)
直接“先清屏、再画网格、最后画波形”会导致严重的屏闪。本代码的绘制逻辑极为精巧,使用了行缓冲(Line Buffer)和分块输出(Blit)。
绘制流程概览
屏幕宽度是301像素,代码将其分为 37个块(Block):
- 前36个块:每块8像素宽。
- 最后1个块:5像素宽。
单块绘制逻辑(核心)
// 以一个块(8x201像素)为例
uint16_t grid_buffer[1608]; // 局部行缓冲
// 步骤1:填充网格背景到缓冲区
for (uint16_t row = 0; row < 201; row++) {
uint8_t byte = grid_data[row][col_block];
// 解析字节中的8个bit,决定像素是网格色还是背景色
*dst++ = (byte & 0x80) ? GRID_COLOR : BG_COLOR;
*dst++ = (byte & 0x40) ? GRID_COLOR : BG_COLOR;
// ... 解析剩余6个bit ...
}
// 步骤2:在网格缓冲区上“叠加”绘制波形线段
// 计算当前块8个像素对应的Y坐标
int16_t y_cols[8] = {0};
// ... 查表填充 y_cols ...
// 绘制波形线(Bresenham算法思想,直接写缓冲区)
for (uint8_t i = 0; i < 7; i++) {
int16_t min_y = min(y_cols[i], y_cols[i+1]);
int16_t max_y = max(y_cols[i], y_cols[i+1]);
// 垂直填充两点之间的所有像素
for (int16_t y = min_y; y <= max_y; y++)
grid_buffer[y * 8 + (i+1)] = WAVE_COLOR;
}
// 步骤3:将这一整块数据一次性推送到LCD硬件
lcd_draw_data(9 + col_block * 8, 19, ... , grid_buffer, 1608);深度机理(无闪烁的关键):
- 离屏缓冲(Off-screen Buffer):
- 所有绘制(网格+波形)都在内存数组
grid_buffer中完成,而不是直接画在屏幕上。
- 所有绘制(网格+波形)都在内存数组
- 原子性块传输(Atomic Blit):
- 当内存中的块准备好后,调用
lcd_draw_data一次性将这 8×201 像素的块推送到LCD的GRAM(图形显存)。 - 对于LCD控制器来说,这是一个单一的写内存操作,非常快。
- 当内存中的块准备好后,调用
- 视觉效果:
- 人眼看不到“清屏-重绘”的过程,只看到一块块稳定的更新,完全消除了屏闪(Tearing)。
3.3 波形参数计算(Calculate_WaveParas)
在显示波形的同时,底层还在计算波形的频率、占空比、峰峰值。
static void Calculate_WaveParas(void) {
// 1. 统计最大最小值(用于峰峰值)
uint8_t current_max = DSO_SAMPLE_SHOW_BUFFER[0];
uint8_t current_min = DSO_SAMPLE_SHOW_BUFFER[0];
uint16_t high_cnt = 0;
for (uint16_t i = 0; i < 601; i++) {
uint8_t val = DSO_SAMPLE_SHOW_BUFFER[i];
if (val > current_max) current_max = val;
if (val < current_min) current_min = val;
// 统计高电平时间(用于占空比)
if (val >= 127 + trigger_offset) high_cnt++;
}
// 2. 计算参数
// 频率:调用外部FFT库函数分析原始采样数据
Wave_Freq = Get_Main_AC_Freq(raw_sorted_buf, ...) / 1000;
// 占空比:简单的高电平点数/总点数
Wave_Duty = (float)high_cnt / 601.0f * 100.0f;
// 峰峰值:(Max-Min)/256 * 每格电压 * 8格
Wave_Vpp = (float)(current_max - current_min) / 256 * (div_base[V_div].div_value * 8);
}深度机理:
- 频率测量:使用了FFT(快速傅里叶变换)。这是频域测量法,相比于时域的“过零点计数”,FFT抗噪声能力更强,尤其适合测量非正弦波的基波频率。
- 占空比测量:基于显示缓冲区的简单统计,统计电压高于阈值的点占总点数的比例。
- 峰峰值测量:利用了
y_lookup的逆逻辑,将像素差还原回电压差。
四、总结
本示波器软件数据链路的核心技术栈如下:
- 采集层:ADC+TIM+DMA环形缓冲,硬件NDTR快照实现预触发。
- 处理层:
- 重排:解决环形缓冲的线性化问题。
- 插值:Catmull-Rom算法实现平滑时基拉伸。
- 抽取:峰值检测算法保留波形细节。
- 显示层:
- LUT:查表法加速坐标映射。
- Blit:分块离屏渲染彻底消除屏闪。
整个流程环环相扣,在有限的MCU资源下实现了专业示波器的显示效果和测量精度。






太强了ヾ(≧∇≦*)ゝ
佩服的五体投地
niu
牛